

以下のような方にオススメの記事です。
- 文字数がバラバラだが、「ー」の前半部分だけを抽出したい
- 文字数がバラバラだが、「@」の後半部分だけを抽出したい
もしも文字数が統一されていれば、MID関数だけで十分に対応できます。
しかし、何文字目から抽出するか・何文字抽出するかがデータによってバラバラだと、MID関数だけでは不十分です。
そこで、MID関数にLEN関数・FIND関数を組み合わせると良いです。
今回のクエストはこちら

LEN関数とFIND関数
頻発する関数ではないけど、今回のケースでは大活躍するよ!
文字列の中で検索文字が何番目にあるか検索したい場合にはFIND関数を利用しましょう。
=FIND( 検索文字 , 文字列 )
機能:文字列の中で検索文字が何番目にあるか
文字列全体の文字数を知りたい場合はLEN関数を利用しましょう。
=LEN ( 文字列 )
機能:文字列の文字数がいくつあるか
「ー」の前半部分のみ文字列を抽出
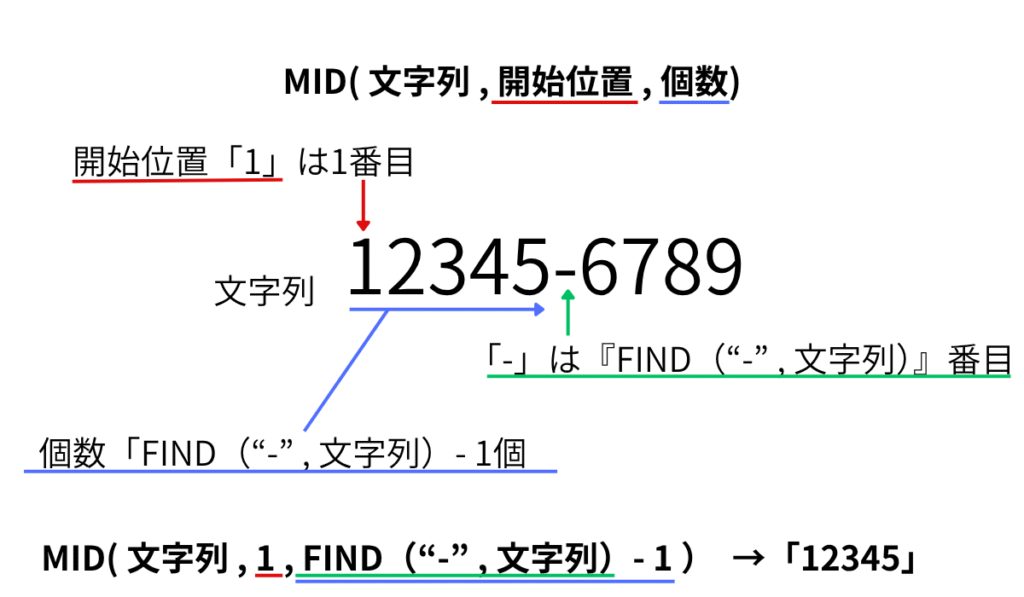
MID関数は「=MID( 文字列 , 開始位置 , 文字数 )」という構成です。
MID関数について確認したい方はこちらをチェックしてください。

前半部分を抽出したいので、開始位置は全て1番目からです。
MID関数では、何文字目から抽出するかは重要だよね!
しかし、「-」までの文字数がバラバラなので、各文字列で何文字を抽出するか算出する必要があります。
何文字を抽出するか
「-」までが何文字あるのか算出するには、「−」が何文字目にあるかが分かれば良いです。
では、特定の文字が文字列の何番目にあるか算出するのはFIND関数です。
これにより、「−」の位置がわかります。
そして、抽出したい文字数は『1番目〜「-」の1つ前まで』です。
ハイフンの1つ前の文字が何番目かを関数で表示したんだね。
MID関数では何文字抽出するかが重要だもんね。
つまり、数式で言えば、「FIND( “-” , 文字列 ) – 1」となります。
前半部分の抽出
以上の要素があれば、前半部分の抽出は可能です。
数式は『=MID( 文字列 , 1 , FIND( “-” , 文字列 ) – 1 ) 』となります。
MID(文字列,開始位置,文字数)に沿うと
「文字列」の「1番目」から「ハイフンの1つ前」までを抽出
って意味になるね。
「ー」の後半部分のみ文字列を抽出
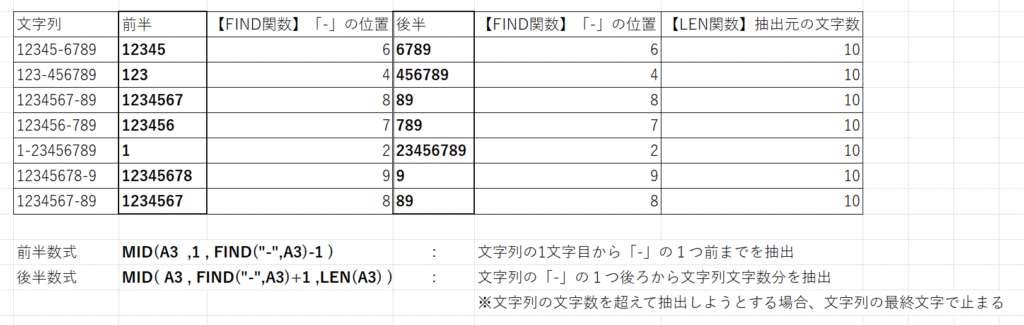
MID関数は「=MID( 文字列 , 開始位置 , 文字数 )」という構成です。
MID関数について確認したい方はこちらをチェックしてください。
後半部分は前半と異なり、開始位置も「-」の位置によって変化します。
どこから抽出し始めるか
開始位置についての考え方は前半と同様です。
「-」の位置の1つ後ろが開始位置になります。
前半部分の抽出は「1文字目から」だったから楽だったのにね。
まずはFIND関数を利用して「-」の位置を特定します。
すると、後半部分の開始位置は『FIND( “-” , 文字列 )+ 1 』番目からということになります。
何文字を抽出するか
MID関数の性質として、抽出する文字数が文字列をオーバーする場合、文字列の最終文字を抽出してストップします。
よって、100など極端に大きい数字に設定する方法が1つです。
何文字抽出するかは、「文字列の最後まで」で良いもんね。
もう少し踏み込んで、どのような場面でも利用できる個数の設定はLEN関数を利用すると良いでしょう。
LEN関数は文字列の全文字数ですので、開始位置がどこであっても必ず最終文字まで抽出できます。
後半部分の抽出
以上の要素があれば、後半部分の抽出は可能です。
数式は『=MID( 文字列 , FIND( “-” , 文字列 ) + 1 , LEN( 文字列 )』となります。
MID(文字列,開始位置,文字数)に沿うと
「文字列」の「ハイフンの1つ後ろ」から「最後まで(文字列の文字数分)」を抽出
って意味になるね。

より正確に抽出文字個数を設定したければ、『LEN(文字列) – FIND( “-” , 文字列 ) 』としても良いですが、そこまでは必要ないでしょう。
【応用】区切りが2種類ある場合
余裕がある人だけ読んでみて!
無理しなくてOK!
データの中に「-」と「@」のように複数の区切り文字が混在し、「どちらか先に登場した区切り文字」を基準に前半部分を抽出したい場合があります。
このとき、複数のFIND関数の結果をMIN関数で包むことで、「最も小さい値(=文字列の中で最も早く出現する位置)」を抽出基準として利用できます。
=MIN( 数値 )
機能:指定した数値から最小値を抽出する
複数の区切り文字で前半部分を抽出
この例では、文字列「東京-大阪」と「札幌@沖縄」の両方に対応し、先に現れた「-」または「@」の直前までを抽出します。
| 項目 | 計算内容 | 数式 |
| 抽出する文字数 | MIN関数で「-」と「@」それぞれの出現位置を調べ、小さい方から 1 を引く。 | =MIN(FIND("-", 文字列), FIND("@", 文字列)) - 1 |
今回のクエストを終えて
MID関数の応用を習得!
規則性はあるが文字数がバラバラな文字列からの抽出はLEN関数やFIND関数を組み合わせる必要があります。
関数同士を組み合わせることは難易度が高くはなりますが、1つずつ図解を利用すれば理解して、使いこなせるようになるでしょう。



コメント